Now scientists can efficiently screen billions of chemical compounds to find effective new drug therapies
Key takeaways:
- New computational technology called “V-SYNTHES” uncovers more effective drug candidates in a fraction of the time other algorithms need.
- The method screens virtual chemical components that can be “clicked” together to build a drug.
- Scientists tested V-SYNTHES on the protein receptors affected by the active ingredient in marijuana, which are a promising family of therapeutic targets.
Searching for molecules that could act as effective therapies for devastating diseases requires extensive time, money and resources — and it often ends in failure.
Researchers at the USC Dornsife College of Letters, Arts and Sciences have created a computer-assisted process that increases the chances of finding effective drugs in a fraction of the time and at significantly less expense than current methods of drug discovery.
The research was published Dec. 15 in the journal Nature.
Puzzling together new, effective drug therapies
Scientists working to create new drugs are equal parts puzzle-solvers and construction workers.
Having peered into a cell and identified a protein that, if manipulated, could help ease or avoid disease, they search for chemical molecules with a specific shape and size, as well as the right features, to fit a target pocket on that protein.
Since they are usually limited to screening just a few million existing molecules that are available “in stock” from vendors, the resulting fit is usually rough and uneven. So, like molecular sculptors, they take an initial rough match, cut away some of its chemical parts and replace them with other parts to shape an “optimized” molecule that better binds to the protein target, neutralizing it or turning it against the disease.
This process — even if done automatically using robotic technology — usually requires significant resources over years of trial and error, and even then it often fails to produce a useful drug. However, new chemical and computer technologies are poised to change the game.
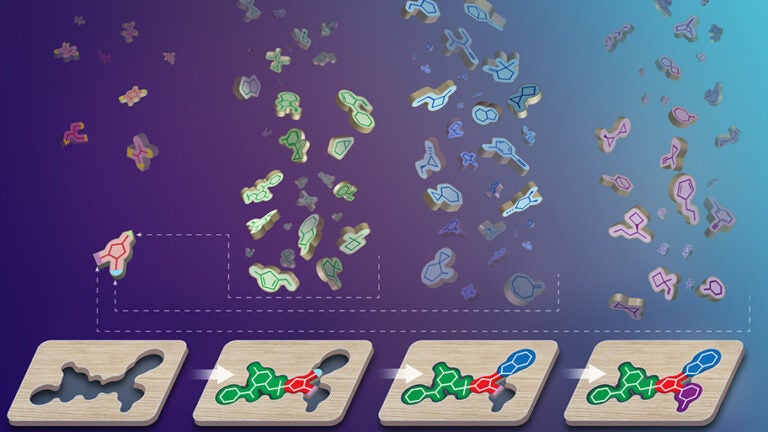
Drawing from a pool of hundreds of thousands of chemical building blocks called synthons, chemists first learned how to use simple and reliable reactions to “click” together two or three synthons at a time to create many billions of molecules of any shape and chemical characteristic. This allowed them to then create virtual catalogs of “readily available for synthesis” compounds — which chemists call “REAL Space” — that are highly likely to include molecules that have a much better initial fit to the protein target.
However, searching for a good initial fit in these enormous, giga-scale libraries creates a problem of its own: Making all of the molecules and testing their fit to the target in the real world would require every chemist in the world to work several lifetimes. Even using modern computational tools to comb through the virtual pile of molecules, now at about 20 billion and rapidly growing, is extremely cumbersome and expensive, creating a new and significant bottleneck for drug discovery.

Vsevolod “Seva” Katritch. (Photo: Courtesy of Vsevold Katritch.)
Enter Vsevolod Katritch, associate professor of quantitative and computational biology and chemistry at USC Dornsife and the USC Michelson Center for Convergent Bioscience.
Katritch leads a group of researchers that developed a new computer-assisted screening approach that bypasses the library size problem by never having to build the full library. Instead, they work directly with the synthons, the virtual building blocks of the REAL Space library, to efficiently puzzle together the best molecules that fit the target.
A better, faster, cheaper way to build a drug molecule
The new method, dubbed “V-SYNTHES” (short for “Virtual Synthon Hierarchical Enumeration Screening”), uses a fraction of the time and computing resources compared to other algorithms for virtual screening of REAL Space libraries.
Instead of screening billions of fully pre-built molecules, V-SYNTHES starts by sifting through the much smaller library of synthons to find those that fit some part of the protein’s target pocket.
Synthons with a good match in one part of the pocket are then “clicked” together with other synthons that may fit the other part.
Repeating this process by adding pieces allows the researchers to build complete molecules and check their fit in the target pocket step by step, greatly facilitating the search for effective drugs.
To test how well V-SYNTHES performs, Katritch and his team, led by USC Dornsife postdoctoral scholar Anastasiia Sadybekov and Arman Sadybekov, formerly at USC Dornsife and now at drug discovery company Schrodinger, first focused on cannabinoid receptors.
Cannabinoid receptors, found throughout the body, are known for mediating the effects of marijuana, but they also are key targets for pain relief and diseases such as cancer, multiple sclerosis and Alzheimer’s and Parkinson’s diseases.
Searching through synthon libraries developed by the chemical company Enamine, V-SYNTHES was more than 5,000 times faster than standard algorithms at finding drug-like molecules that could selectively target cannabinoid receptors.
Further, when the predicted drug candidates were synthesized and then tested in the lab, the number that actually worked — meaning those that effectively bound and blocked the cannabinoid receptors — was twice that of the candidates suggested by standard search algorithms.
Repeating the search to find other molecules that were similar to their first round of best hits, Katritch’s lab identified even more potent molecules that may work in clinical settings.
“V-SYNTHES doubled our success rate and helped to find very potent drug candidates with clinically relevant binding affinities,” Katritch said.
Katritch and his team collaborated with Nicos Petasis, professor of chemistry and pharmacology at USC Dornsife, to further test V-SYNTHES using another important protein target called ROCK1, which is linked to cancer.
The researchers note that the algorithm should work for any target protein with a well-characterized 3D structure that the algorithm can analyze and match to synthon combinations.
Exploring the expanding chemical universe
While the current study uses V-SYNTHES to screen a version of Enamine’s REAL Space library with 11 billion molecules, the researchers say that theoretically it can be scaled up many more orders of magnitude.
Katritch noted that the rapid growth of the REAL Space molecular libraries makes the speed and scalability of this new algorithm increasingly valuable.
“The REAL space library doubled to 21 billion compounds in just one year, and this number will grow polynomially when it expands to molecules built with four or five synthons, not just two- or three-synthon molecules considered now,” he said, noting the library could expand to trillions or even quadrillions of molecules.
“This is a good problem to have, but we’ll need to be able to very rapidly and efficiently narrow the choices if we want to find viable drug candidates in this ocean of molecules,” something V-SYNTHES is designed to do, he said.

Anastasiia (left) and Arman Sadybekov contributed to the V-SYNTHES research. (Photos: Courtesy of the Sadybekovs.)
The cost of screening more combinations using standard methods multiplies every time another synthon joins the mix. The cost of V-SYNTHES, in contrast, increases much more slowly, by a fixed amount for each additional synthon. But there is room for improvement, Katritch says. While the process of using V-SYNTHES currently requires substantial human attention, the team is now working to upgrade V-SYNTHES to fully automate the process.
Katritch also aims to use V-SYNTHES to screen for drug candidates targeting other proteins that are involved with a variety of intractable diseases, collaborating with researchers both at USC and other institutions. Moreover, V-SYNTHES can be implemented in the biotech and pharmaceutical industries, where streamlined drug discovery can best benefit patients in need of new and better therapies.
About the study
In addition to the researchers mentioned above, authors on the study include Blake Houser and Nilkanth Patel at USC Dornsife; Bryan Roth, Yongfeng Liu, Xi-Ping Huang, Julie Pickett and Manish Jain of the University of North Carolina at Chapel Hill School of Medicine; Alexandros Makriyannis, Christos Iliopoulos-Tsoutsouvas, Ngan Tran, Fei Tong, Nikolai Zvonok, Spyros Nikas of Northeastern University; Olena Savych of Enamine Ltd.; Dmytro Radchenko of Enamine and Taras Shevchenko National University of Kyiv; Yurii S. Moroz of Taras Shevchenko of National University of Kyiv and Chemspace LLC.
The study was funded by National Institute on Drug Abuse grants R01DA041435 and R01DA045020; National Institute of Mental Health grant R01MH112205 and Psychoactive Drug Screening Program; and National Institute of General Medical Sciences grant T32-GM118289.